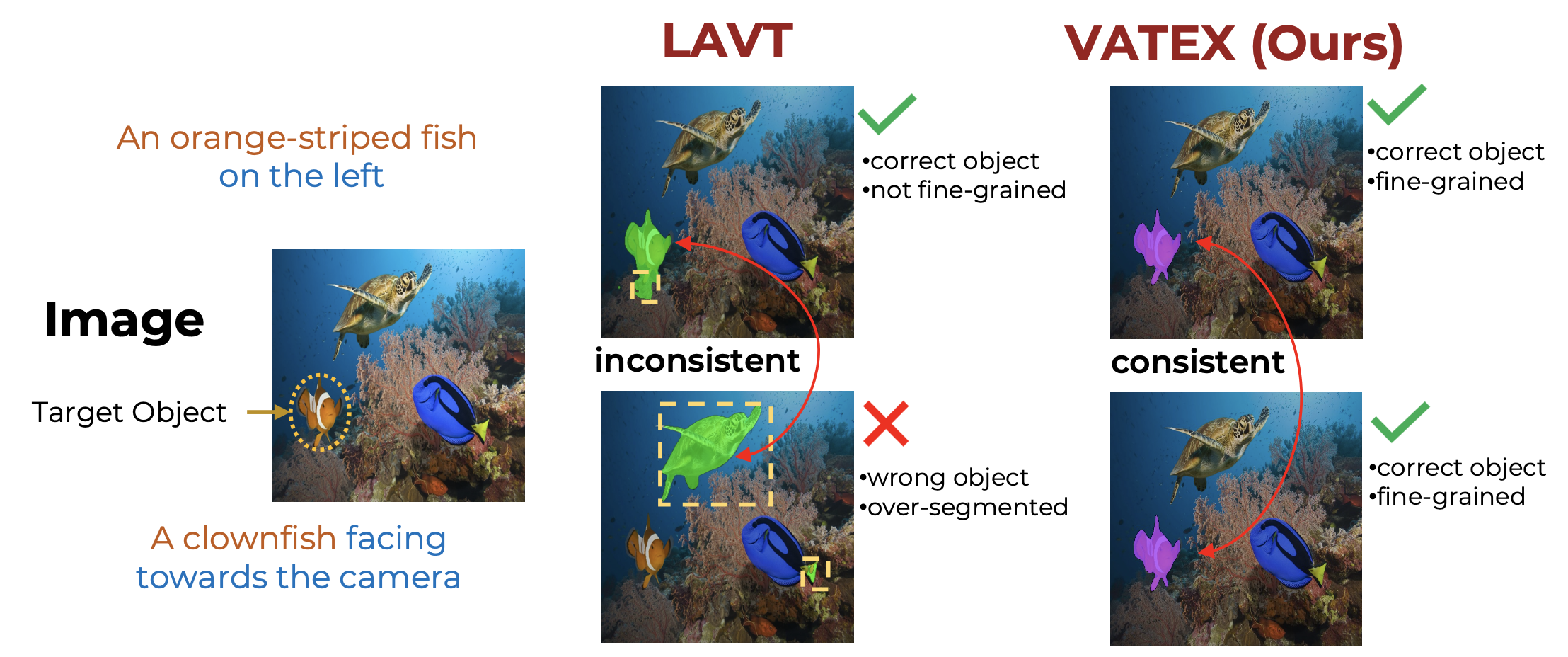
Referring image segmentation is a challenging task that involves generating pixel-wise segmentation masks based on natural language descriptions. The complexity of this task increases with the intricacy of the sentences provided.
Existing methods have relied mostly on visual features to generate the segmentation masks while treating text features as supporting components. However, this under-utilization of text understanding limits the model's capability to fully comprehend the given expressions.
In this work, we propose a novel framework that specifically emphasizes object and context comprehension inspired by human cognitive processes through Vision-Aware Text Features.
We introduce a CLIP Prior module to localize the main object of interest and embed the object heatmap into the query initialization process.
We propose a combination of two components: Contextual Multimodal Decoder (CMD) and Meaning Consistency Constraint (MCC), to further enhance the coherent and consistent interpretation of language cues.
✨ Results:
Our method achieves significant performance improvements on three benchmark datasets RefCOCO, RefCOCO+ and G-Ref.
🚀 Code Released:
Our code and pre-trained weights are available at https://github.com/nero1342/VATEX.
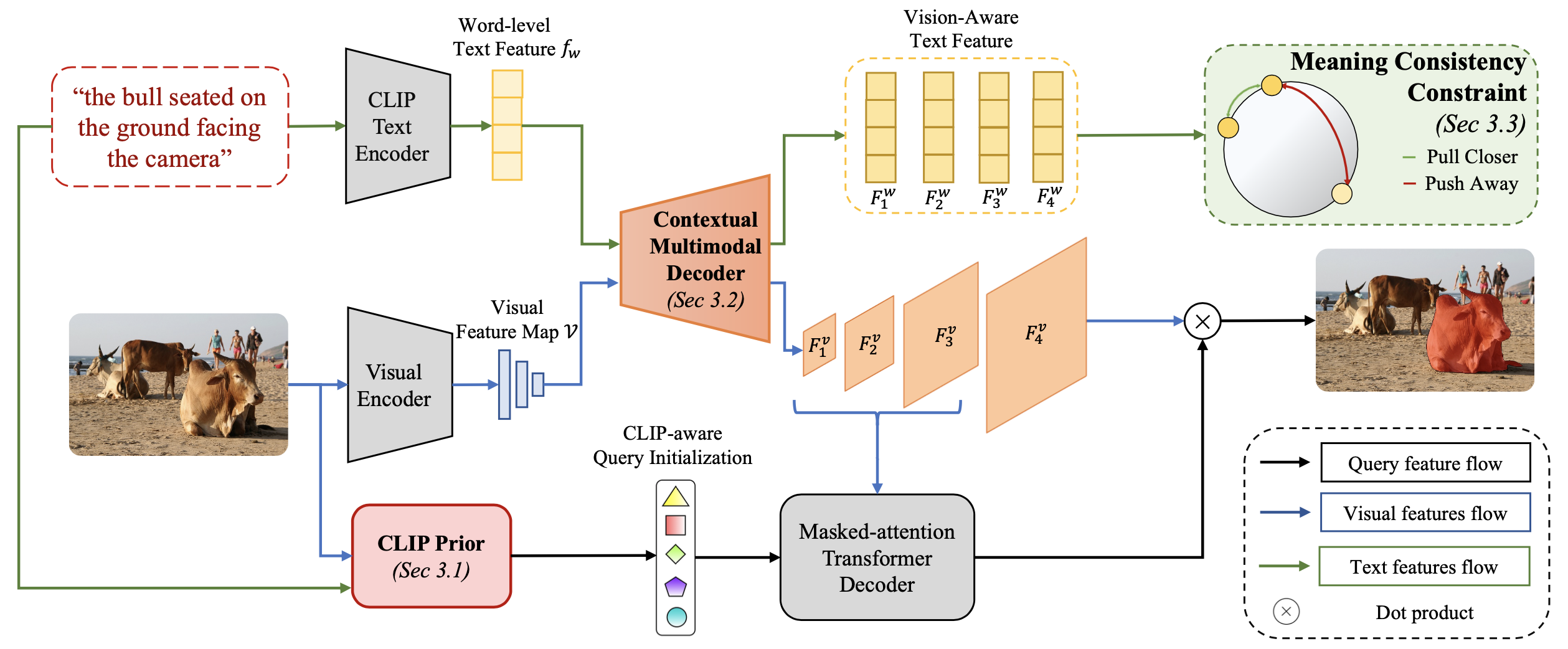
The overall framework of VATEX processes input images and language expressions through two concurrent pathways.
Initially, the CLIP Prior module generates object queries,
while simultaneously, traditional Visual and Text Encoders create multiscale visual feature maps and
word-level text features. These visual and text features are passed into the
Contextual Multimodal Decoder (CMD) to enable multimodal interactions, yielding vision-aware text features and text-enhanced
visual features. We then harness vision-aware text features to ensure semantic consistency across varied textual descriptions that
reference the same object by employing sentence-level contrastive learning, as described in the
Meaning Consistency Constraint (MCC) section. On the other hand, the text-enhanced visual features and the object queries generated
by the CLIP Prior are refined through a Masked-attention Transformer Decoder to produce the final output segmentation masks.
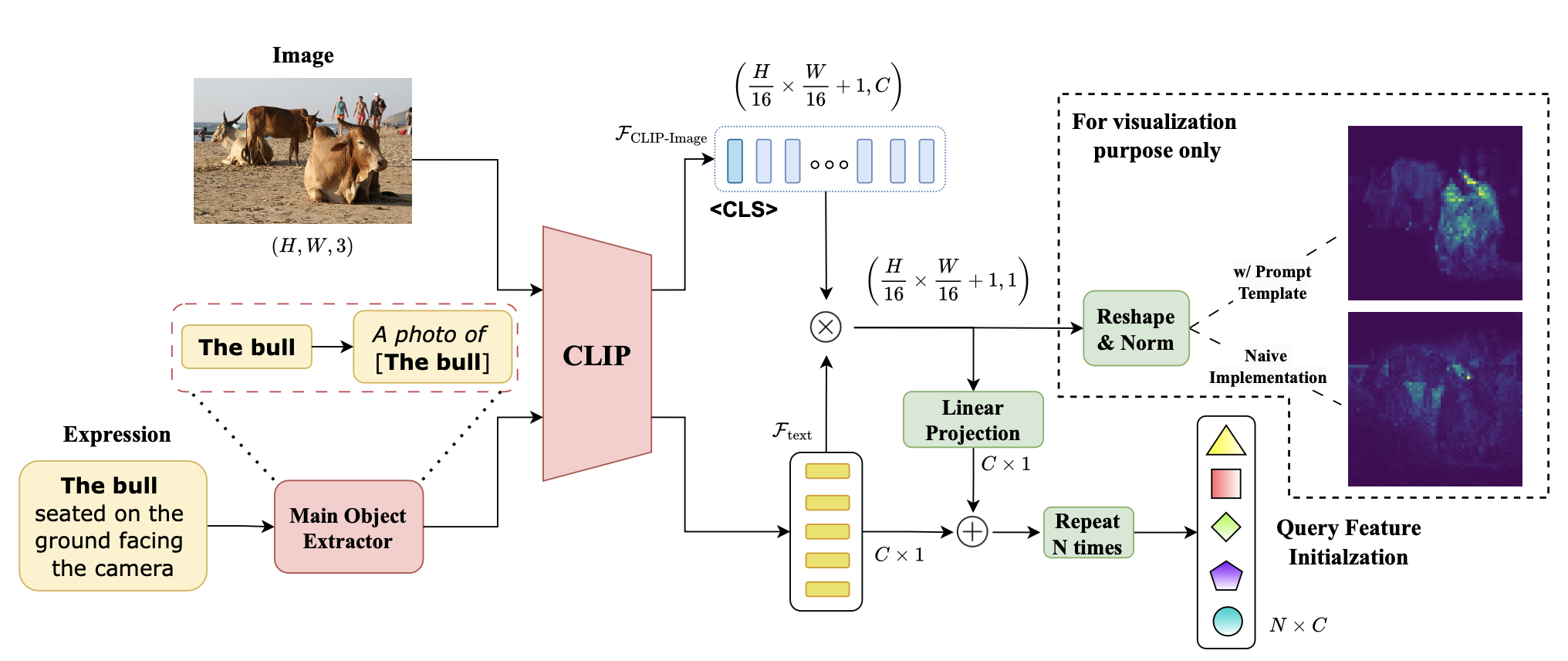
The CLIP Prior module leverages the powerful visual-semantic alignment capabilities of CLIP to generate initial object queries. By utilizing CLIP's pre-trained knowledge, we can better localize objects mentioned in the referring expressions before detailed segmentation , especially for out-of-vocabulary objects.
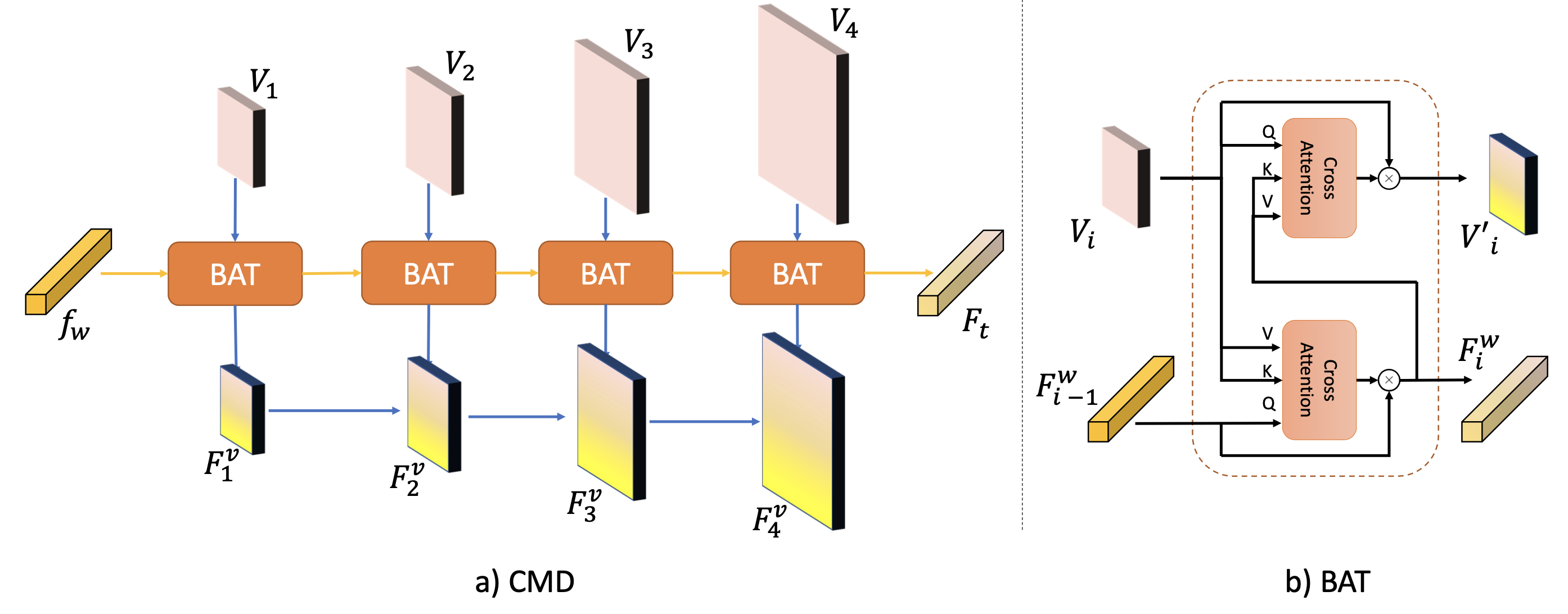
The CMD module enables multimodal interactions by integrating visual and text features, allowing the model to understand the semantic relationships between visual and textual cues.
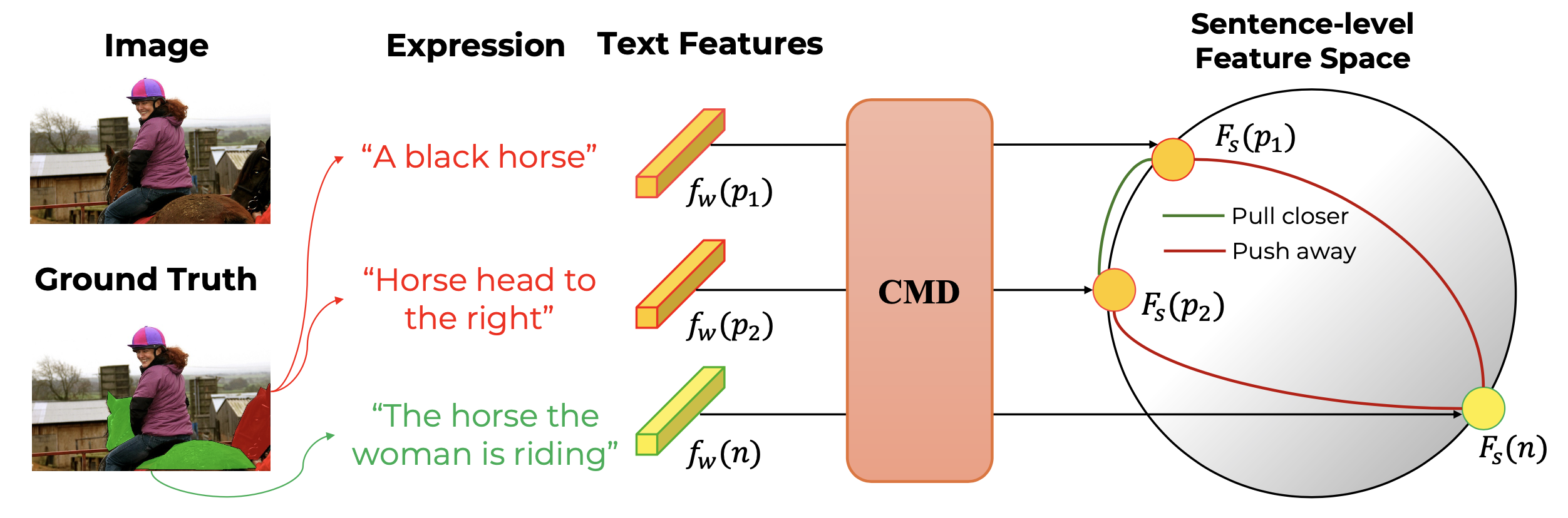
The MCC component ensures semantic consistency by employing contrastive learning at the sentence level. This helps the model understand that different textual descriptions referring to the same object should map to similar semantic representations, improving robustness and generalization.
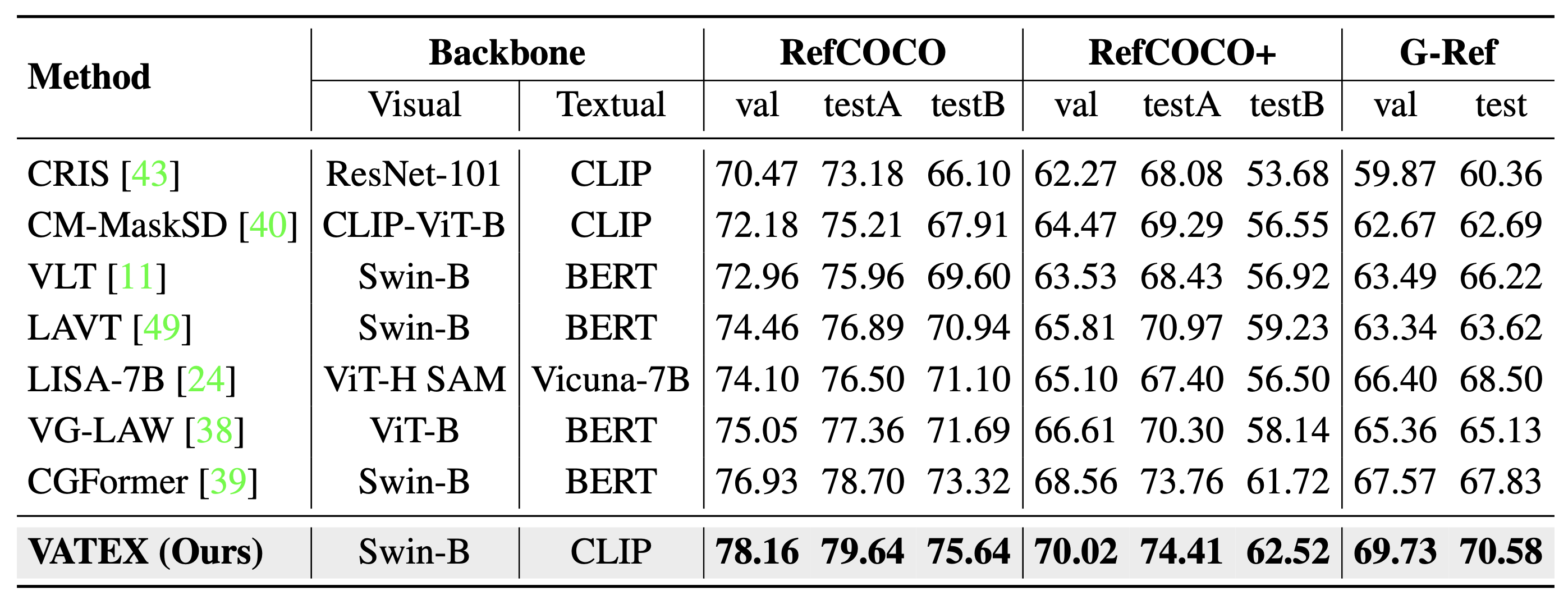
As shown in the table, our method achieves remarkable performance improvements over state-of-the-art methods across all benchmarks on mIoU metrics. Notably, we surpass recent methods like CGFormer and VG-LAW by substantial margins: +1.23% and +3.11% on RefCOCO, +1.46% and +3.31% on RefCOCO+, and +2.16% and +4.37% on G-Ref validation splits respectively. The more complex the expressions, the greater the performance gains achieved by VATEX. Even compared to LISA, a large pre-trained vision-language model, VATEX consistently achieves an impressive 3-5% better performance across all datasets.

Our visualizations demonstrate VATEX's superior performance in complex visual reasoning scenarios. The model excels at:
• Distinguishing Similar Objects: Successfully differentiates between multiple similar instances (e.g., 1st column: identifying the seated person vs. standing person on a tennis court).
• Fine-grained Recognition: Precisely locates specific items among visually similar alternatives (e.g., 2nd column: distinguishing a particular sushi plate among various food dishes).
• Detailed Segmentation: Captures intricate object details beyond ground truth annotations (e.g., 4th column: complete umbrella shaft segmentation).
• Accurate Object Relationships: Better understands complex interactions (e.g., 6th & 7th column: correctly segmenting the bear in "bear child is hugging" and "bear with 59 tag" scenario).
Our instance-based architecture produces smoother, more complete masks compared to LAVT and CRIS's pixel-based approach.
@InProceedings{Nguyen-Truong_2025_WACV,
author = {Nguyen-Truong, Hai and Nguyen, E-Ro and Vu, Tuan-Anh and Tran, Minh-Triet and Hua, Binh-Son and Yeung, Sai-Kit},
title = {Vision-Aware Text Features in Referring Image Segmentation: From Object Understanding to Context Understanding},
booktitle = {Proceedings of the Winter Conference on Applications of Computer Vision (WACV)},
month = {February},
year = {2025},
pages = {4988-4998}
}
}